
MiDashengLM-7B是什么
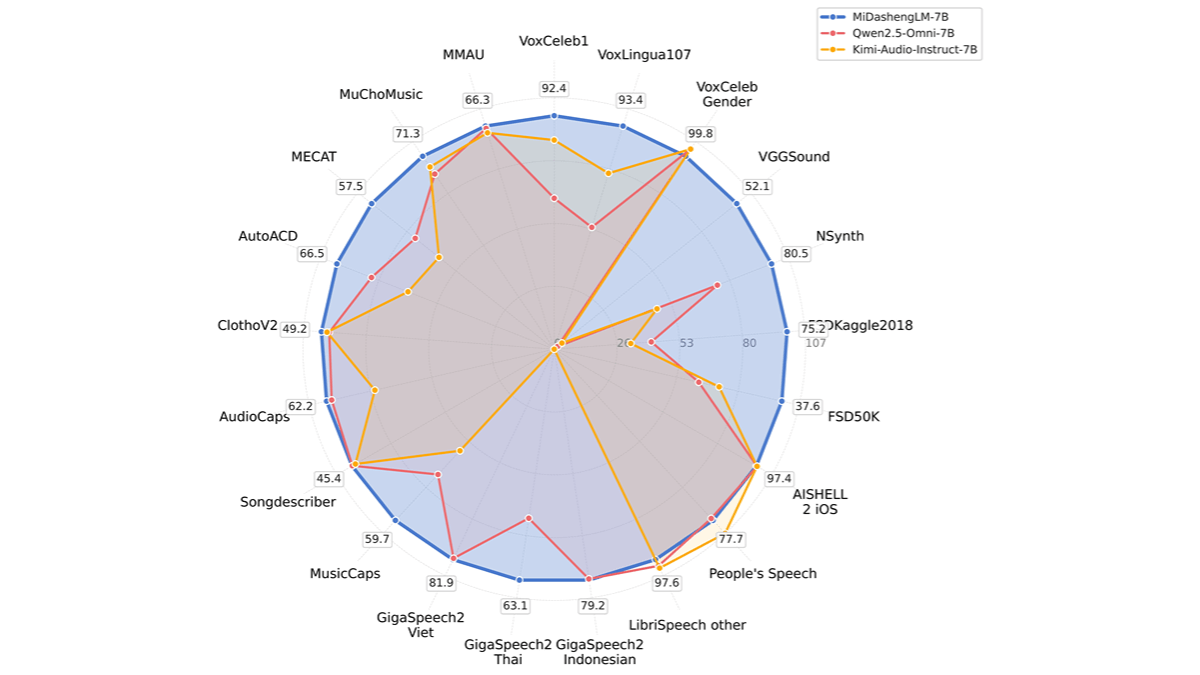
MiDashengLM-7B 是小米发布的开源声音理解大模型,参数规模为 70 亿。模型基于 Xiaomi Dasheng 音频编码器和 Qwen2.5-Omni-7B Thinker 解码器,采用创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。在 22 个公开评测集上刷新了多模态大模型的最好成绩,单样本推理的首 Token 延迟仅为业界先进模型的 1/4,同等显存下的数据吞吐效率是业界先进模型的 20 倍以上。训练数据完全来自公开数据集,以 Apache License 2.0 发布,支持学术和商业应用。
MiDashengLM-7B的主要功能
-
通用音频理解:能理解各种音频内容,包括人类语音、环境声音和音乐。
-
跨模态融合:结合音频输入与文本提示,生成相关的文本响应,支持音频到文本的理解。
-
情绪与音乐理解:可识别说话者的情绪和音乐元素,提供更丰富的交互体验。
-
高效推理:具备低延迟和高吞吐效率的推理能力,适合实时应用。
MiDashengLM-7B的官网地址
- GitHub仓库:https://github.com/xiaomi-research/dasheng-lm
- HuggingFace模型库:https://huggingface.co/mispeech/midashenglm-7b
- 技术论文:https://github.com/xiaomi-research/dasheng-lm/blob/main/technical_report/MiDashengLM_techreport.pdf
- 在线体验Demo:https://huggingface.co/spaces/mispeech/MiDashengLM-7B
MiDashengLM-7B相关的人工智能知识
-
声音理解:声音理解是人工智能中对音频信号进行分析和解释的技术,包括语音识别、环境声音识别等。MiDashengLM-7B 通过音频编码器对声音进行特征提取和理解,能处理多种类型的音频输入。
-
多模态融合:多模态融合是指将不同模态的数据(如音频和文本)结合起来进行处理和分析。MiDashengLM-7B 能将音频输入与文本提示相结合,生成相关的文本响应,体现了多模态融合的能力。
-
大模型架构:大模型是指参数规模庞大的人工智能模型,具有强大的学习和生成能力。MiDashengLM-7B 的参数规模为 70 亿,采用了先进的音频编码器和解码器架构,具备较高的性能。
-
训练与优化:模型的训练是通过大量的数据和优化算法来调整模型参数,能更好地完成任务。MiDashengLM-7B 采用了通用音频描述对齐范式进行训练,通过优化推理效率,实现了低延迟和高吞吐。
-
推理效率:推理效率是指模型在实际应用中对输入数据进行处理和生成响应的速度。MiDashengLM-7B 在推理效率方面表现出色,能在短时间内给出准确的响应,适合实时交互场景。
相关文章
暂无评论...