
DINOv3是什么
DINOv3 是 Meta AI 推出的自监督视觉基础模型,采用自监督学习范式,无需标注数据即可学习图像特征。通过改进数据准备和引入 Gram anchoring 解决了特征退化问题,提升泛化能力。DINOv3 提供 ViT 和 ConvNeXt 两种骨干网络架构,其中 ViT-7B 是目前规模最大的版本,包含 67 亿参数。模型能生成高质量的密集特征表示,精准捕捉图像的局部关系和空间信息。在图像分类、目标检测、语义分割等多种视觉任务中表现出色,无需任务特定微调即可超越许多专业模型。
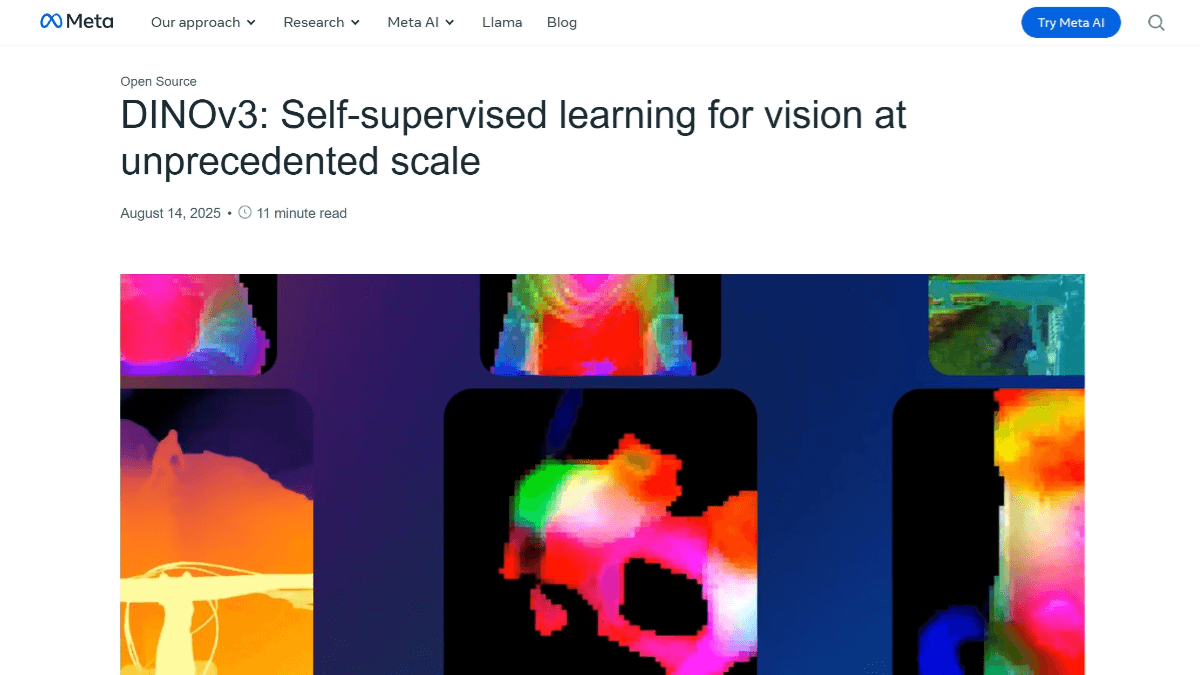
DINOv3的主要功能
-
自监督学习:通过自监督机制,无需标注数据即可学习图像特征,解决特征退化问题,提升泛化能力。
-
高质量特征提取:生成密集特征表示,精准捕捉图像局部关系和空间信息,适用于多种视觉任务。
-
多任务通用性:在图像分类、目标检测、语义分割等任务中表现出色,无需任务特定微调即可快速部署。
-
高分辨率特征支持:支持高分辨率特征提取,适用于医学影像分析、环境监测等需要高精度特征的场景。
DINOv3的官网地址
- 项目官网:https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
- HuggingFace模型库:https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- 技术论文:https://ai.meta.com/research/publications/dinov3/
DINOv3相关的人工智能知识
-
自监督学习:自监督学习是一种无监督学习方法,通过设计预训练任务让模型从数据本身学习特征表示,无需依赖大量标注数据。DINOv3 利用自监督学习解决了大规模标注数据依赖问题,提升了模型的泛化能力,能在未标注数据中自动学习有用的特征。
-
视觉 Transformer(ViT):视觉 Transformer 是一种将 Transformer 架构应用于计算机视觉领域的模型,能处理图像中的局部和全局信息。DINOv3 提供了基于 ViT 的骨干网络架构,用于高效提取图像特征,相比传统卷积网络,ViT 在处理长距离依赖关系时具有优势。
-
特征提取与表示:特征提取是计算机视觉中的关键环节,模型通过学习生成高质量的特征表示,能精准捕捉图像的局部关系和空间信息。DINOv3 的特征提取能力使其在多种视觉任务中表现出色,为后续任务提供了坚实的基础。
-
多任务学习:多任务学习是指模型能同时处理多个相关任务,共享特征表示以提升性能。DINOv3 能在图像分类、目标检测、语义分割等任务中表现出色,无需针对每个任务进行特定微调,体现了其多任务通用性,降低了开发成本。
-
高分辨率特征:高分辨率特征提取是指模型能生成高精度的特征图,保留更多细节信息。DINOv3 支持高分辨率特征提取,适用于医学影像分析、环境监测等需要高精度特征的场景,能帮助模型更好地理解图像内容。
-
预训练与微调:预训练是指模型在大规模数据上进行初步训练以学习通用特征,微调是指针对具体任务进行进一步优化。DINOv3 虽然无需任务特定微调即可表现出色,但用户也可以根据具体任务需求进行微调,进一步提升性能。
相关文章
暂无评论...