
VibeVoice是什么
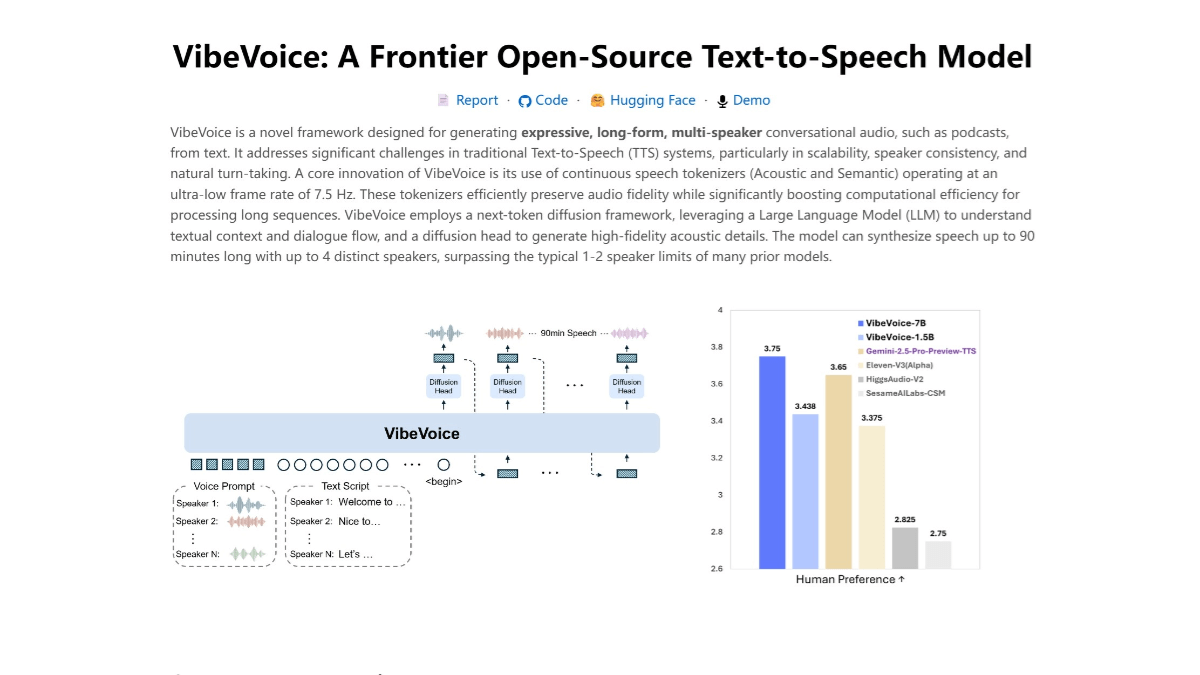
VibeVoice是微软研究院开源的文本转语音模型,专注于生成长篇、富有表现力的多说话人对话音频,例如播客。有效解决了传统TTS系统在可扩展性、说话人一致性和自然对话流方面的难题。VibeVoice通过创新性地使用超低帧率连续语音分词器(声学和语义),结合一个利用大语言模型理解文本上下文和对话流的下一代Token扩散框架,实现了长达90分钟的语音合成和支持最多4个不同说话人的能力,展现了跨语言和自发歌唱的潜力。
VibeVoice的主要功能
-
长篇多说话人对话生成:VibeVoice能生成长达90分钟的多说话人对话音频,最多支持4个不同说话人,突破了传统TTS系统在说话人数量和对话长度上的限制,适合制作播客等长篇对话内容。
-
跨语言合成:支持英文和中文的文本输入,能生成对应语言的语音,满足不同语言场景下的语音合成需求。
-
情感丰富的语音表达:通过大语言模型理解文本上下文和对话流,结合扩散模型生成高保真的声学细节,使合成语音更具情感和表现力,能更好地传达文本中的情绪和语气。
-
高效计算与低延迟:采用超低帧率的连续语音分词器,有效提升了计算效率,降低了延迟,使长篇语音合成更加流畅和高效,适合实时或近实时的语音生成场景。
-
灵活的语音合成控制:用户可以通过简单的文本输入和角色标识,控制不同说话人的语音特征和对话内容,实现个性化的语音合成,满足多样化的语音生成需求。
VibeVoice的官网地址
- 项目官网:https://microsoft.github.io/VibeVoice/
- GitHub仓库:https://github.com/microsoft/VibeVoice
- HuggingFace模型库:https://huggingface.co/collections/microsoft/vibevoice-68a2ef24a875c44be47b034f
- 技术论文:https://github.com/microsoft/VibeVoice/blob/main/report/TechnicalReport.pdf
VibeVoice相关的人工智能知识
-
文本转语音(TTS)技术:是一种将文字转换为语音的人工智能技术,让机器能“说话”。VibeVoice作为TTS系统,可把文本变成自然流畅的语音,像播客里的对话一样。
-
深度学习模型:是人工智能的核心,通过大量数据训练模型来执行特定任务。VibeVoice用大语言模型理解文本意思,用扩散模型生成逼真语音,让机器生成的语音像真人一样自然。
-
语音分词器:是处理语音信号的关键工具,VibeVoice的语音分词器在低帧率下工作,能高效处理长文本,保持语音质量的同时提高计算效率。
-
多说话人语音合成:VibeVoice可以处理多个说话人的对话,最多支持4个不同说话人,要求模型区分和保持每个说话人的独特语音特征,让对话听起来自然。
-
情感和表现力:VibeVoice能根据文本内容传达情感和表现力,让语音更生动自然,比如在对话中表现出高兴、生气等情绪。
-
实时语音合成:VibeVoice支持实时或近实时的语音合成,对于需要即时反馈的应用场景至关重要,要求模型快速处理和生成语音,保持语音质量。
相关文章
暂无评论...