
FastVLM是什么
FastVLM(Fast Vision Language Model)是苹果公司推出的视觉语言模型。以FastViTHD混合视觉编码器为核心,融合了卷积和Transformer架构,可显著减少视觉token数量,降低编码时间和延迟。在处理高分辨率图像时,编码速度比同类模型快85倍,首次token生成时间(TTFT)提升了3.2倍,视觉编码器尺寸更小,方便在移动设备上部署。
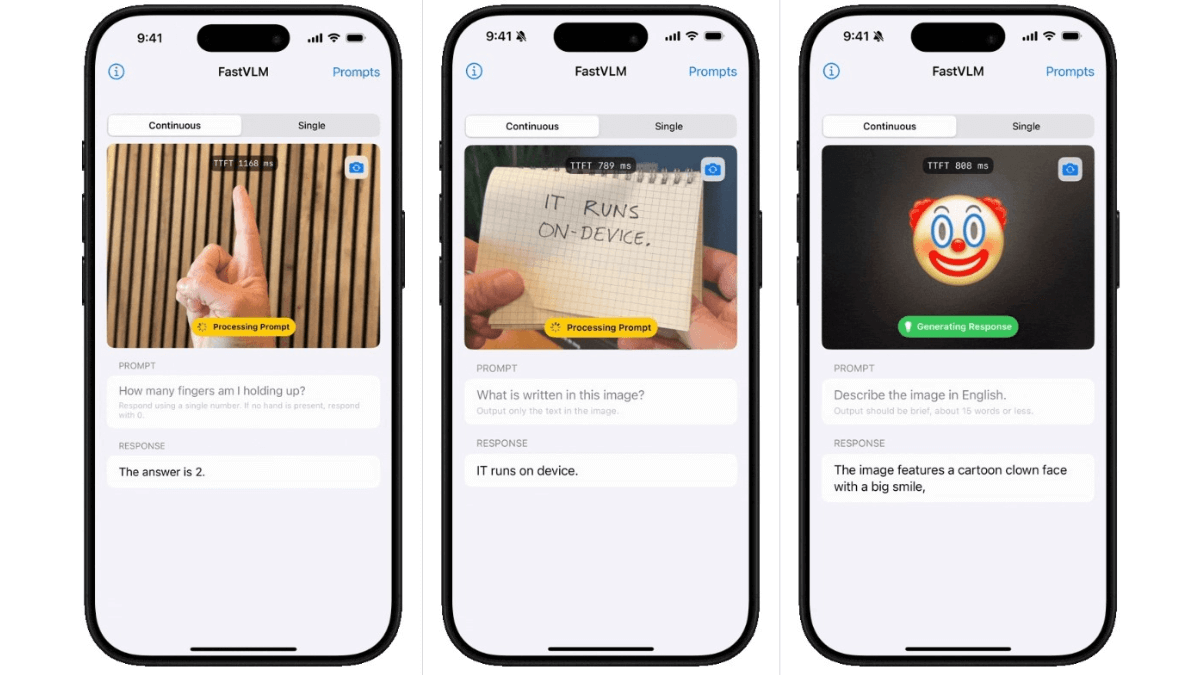
FastVLM的主要功能
-
高效视觉编码:FastVLM采用FastViTHD混合视觉编码器,结合卷积和Transformer架构,大幅减少视觉token数量,降低编码时间和延迟,尤其在高分辨率图像处理上表现出色,编码速度显著提升。
-
低延迟响应:在LLaVA-1.5设置中,FastVLM的首次token生成时间(TTFT)显著缩短,响应速度快,适合实时交互场景,如移动端图文问答助手,能够快速给出答案。
-
模型尺寸优化:视觉编码器尺寸大幅缩小,比同类模型小3.4倍,便于在移动设备和边缘智能设备上部署,降低了硬件要求,提高了模型的可移植性。
-
高准确性:在多种基准测试中,FastVLM的性能与更大模型相当,能够准确理解和生成与图像相关的内容,保证了模型的实用性。
-
简化设计:仅通过缩放输入图像尺寸实现token数量和分辨率的平衡,无需额外的token剪枝,简化了模型设计,降低了复杂度,提高了开发和部署的效率。
FastVLM的官网地址
- GitHub仓库:https://github.com/apple/ml-fastvlm
- HuggingFace模型库:https://huggingface.co/collections/apple/fastvlm-68ac97b9cd5cacefdd04872e
- arXiv技术论文:https://www.arxiv.org/pdf/2412.13303
FastVLM相关的人工智能知识
-
视觉语言模型(VLM):视觉语言模型是一种结合了计算机视觉和自然语言处理的人工智能模型,能理解和生成与图像相关的内容。模型可以处理图像识别、图像描述生成、图文问答等任务,使机器能像人类一样理解和表达图像信息。
-
混合编码器架构:混合编码器架构融合了卷积神经网络(CNN)和Transformer架构的优点。CNN擅长提取图像的局部特征,Transformer能捕捉全局依赖关系,这种结合可以有效提升模型对图像和文本的综合理解能力。
-
动态token剪枝:动态token剪枝是一种优化技术,通过动态调整模型中的token数量,去除冗余信息,减少计算量和内存占用。这种方法可以在不显著降低模型性能的前提下,提高模型的运行效率,特别适用于资源受限的设备。
-
模型压缩与优化:模型压缩与优化是指通过减少模型的参数数量和计算复杂度,更适合在移动设备和边缘设备上运行。这包括剪枝、量化等技术,保持模型性能的同时降低硬件要求。
-
-
自然语言处理(NLP):自然语言处理是人工智能的一个分支,专注于使计算机能够理解和生成人类语言。包括文本分类、情感分析、机器翻译、问答系统等任务,是实现人机交互的关键技术之一。
-
计算机视觉(CV):计算机视觉是人工智能的另一个重要分支,使计算机能像人类一样理解和解释图像和视频。包括图像识别、目标检测、图像分割等任务,广泛应用于自动驾驶、安防监控、医疗影像等领域。
-
实时交互技术:实时交互技术确保模型能快速响应用户的输入,提供即时的反馈。对于需要即时交互的应用场景(如智能客服、实时翻译、移动助手等)至关重要,能显著提升用户体验。
相关文章
暂无评论...