
AnyI2V是什么
AnyI2V是复旦大学联合阿里巴巴达摩院等机构推出的创新图像动画生成框架,能将静态图像(如网格、点云)转化为动态视频,无需大量训练数据,支持用户自定义运动轨迹。AnyI2V通过DDIM反演提取特征,结合运动控制生成动画,支持多模态输入和灵活编辑。AnyI2V在动画制作、视频特效、游戏开发等领域有广泛应用,为创作者提供高效、灵活的动画生成新方法。
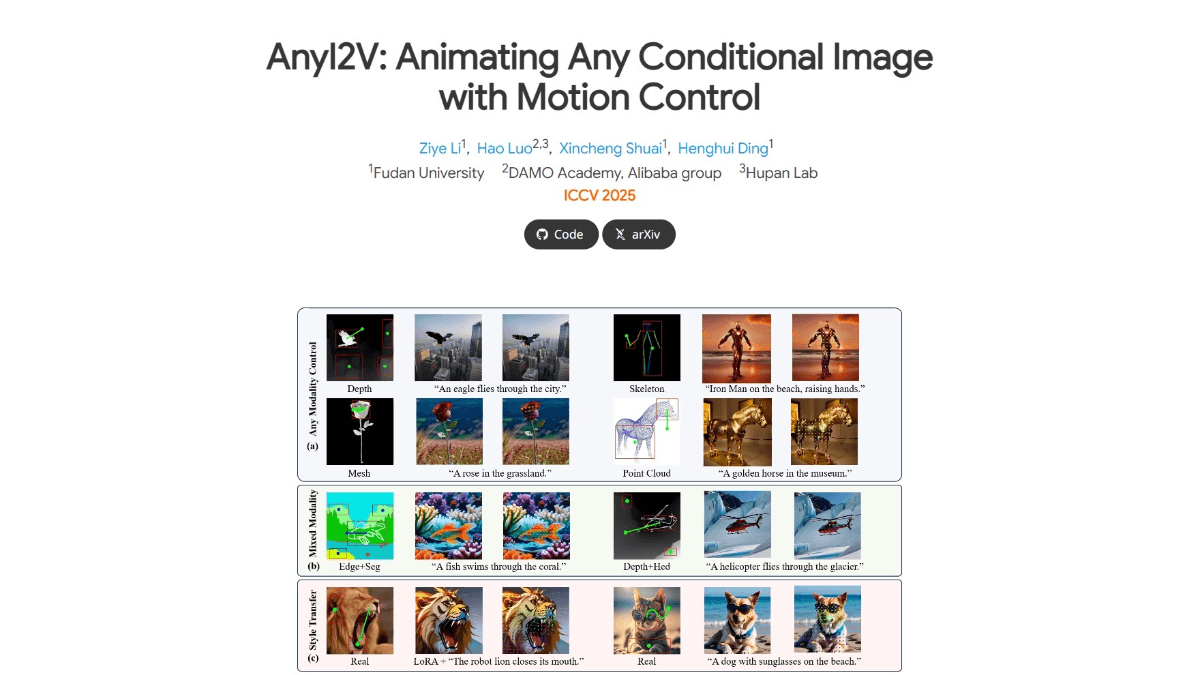
AnyI2V的主要功能
-
多模态输入:AnyI2V支持多种类型的条件输入,如网格、点云等难以获取成对的训练数据的模态。
-
混合条件输入:能同时接受不同类型的条件输入组合,极大地增加输入的灵活性。
-
灵活编辑:通过LoRA或不同的文本提示,支持对原始图像进行风格迁移和内容调整。
-
运动控制:用户能定义运动轨迹,精确控制视频中对象的运动路径。
-
无需训练:框架无需大量训练数据和复杂的训练过程,降低使用门槛。
AnyI2V的官网地址
- 项目官网:https://henghuiding.com/AnyI2V/
- GitHub仓库:https://github.com/FudanCVL/AnyI2V
- arXiv技术论文:https://arxiv.org/pdf/2507.02857
AnyI2V相关的人工智能知识
- 扩散模型(Diffusion Models):扩散模型是生成模型,通过逐步去除噪声恢复图像。模型从一个完全噪声的图像开始,逐步减少噪声,最终生成清晰的图像。AnyI2V用DDIM(Denoising Diffusion Implicit Model)反演技术,从条件图像中提取特征,用在后续的动画生成。
- 条件图像(Conditional Images):条件图像是生成模型中用在指导生成过程的输入图像。在AnyI2V中,条件图像能是网格、点云等,图像提供生成动画的基础信息。通过DDIM反演,AnyI2V能从条件图像中提取特征,用在生成动态视频。
- 特征提取(Feature Extraction):特征提取是从输入数据中提取有用信息的过程。AnyI2V在处理条件图像时,移除3D U-Net中的时间模块,专注于提取空间特征。空间特征被用在优化潜在表示,确保生成的动画符合用户定义的运动轨迹。
- 潜在表示(Latent Representation):潜在表示是输入数据在模型中的抽象表示。在AnyI2V中,提取的特征被替换回3D U-Net中,优化潜在表示。通过自动生成的语义掩码进行约束,确保优化只在特定区域进行,提高生成效果的准确性。
相关文章
暂无评论...