
XTuner V1是什么
XTuner V1 是上海人工智能实验室开源的新一代大模型训练引擎,专为超大规模稀疏混合专家(MoE)模型训练设计。基于 PyTorch FSDP 开发,通过显存、通信和负载等多维度优化,实现了高性能训练。XTuner V1 支持高达1万亿参数的MoE模型训练,在2000亿以上量级模型上,训练吞吐量首次超越传统3D并行方案。支持64k长序列训练,无需序列并行技术,显著降低了专家并行依赖,提升了长序列训练效率。
XTuner V1的主要功能
-
无损训练:XTuner V1 能够在不使用专家并行的情况下训练2000亿规模的MoE模型,6000亿模型仅需节点内专家并行,显著降低了训练复杂度和资源需求。
-
长序列支持:无需序列并行技术,即可实现2000亿MoE模型的64k序列长度训练,更适合当下流行的强化学习训练场景,提升了模型在长文本处理等任务中的表现。
-
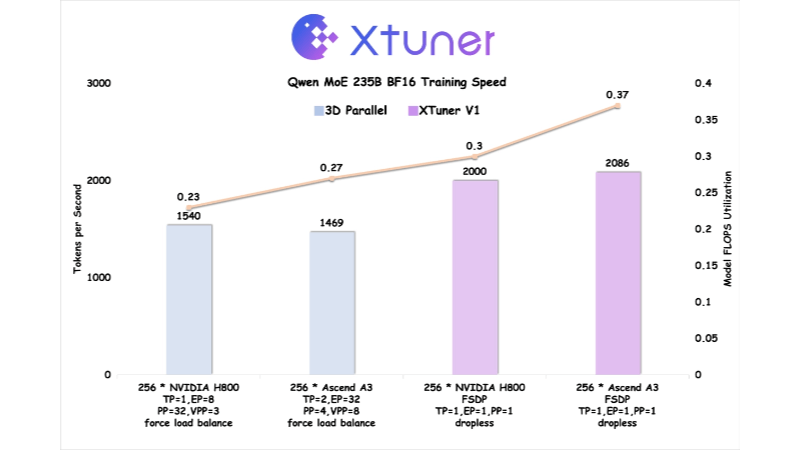
高效率:支持高达1万亿参数的MoE模型训练,并在2000亿以上量级的混合专家模型上,首次实现训练吞吐超越传统的3D并行训练方案,大幅提高了训练速度和效率。
-
显存优化:通过自动Chunk Loss机制和Async Checkpointing Swap技术,显著降低显存峰值,支持2000亿参数量级MoE模型训练64K长度序列,优化了资源利用。
-
通信掩盖:通过极致的显存优化和Intra-Node Domino-EP技术,增加每层计算的耗时,掩盖参数聚合的通信耗时,减少了通信开销对训练效率的影响。
-
DP负载均衡:通过特定算法,缓解变长注意力带来的计算空泡问题,确保数据并行维度的负载均衡,进一步提升了训练效率。
-
硬件协同优化:与华为昇腾技术团队合作,在Ascend A3 NPU超节点上进行了深度优化,即使在理论算力落后NVIDIA H800近20%的情况下,也能实现训练吞吐量反超H800近5%,MFU反超20%以上,充分发挥了硬件性能。
XTuner V1的官网地址
- 项目官网:https://xtuner.readthedocs.io/zh-cn/latest/
- GitHub仓库:https://github.com/InternLM/xtuner
XTuner V1相关的人工智能知识
-
混合专家模型(MoE):混合专家模型是一种将模型参数划分为多个专家模块的架构,每个专家模块只处理部分输入数据。这种架构通过稀疏激活机制,只激活部分专家进行计算,实现高效的并行计算和参数扩展,适用于大规模模型训练。
-
稀疏激活机制:在MoE模型中,稀疏激活机制允许只有部分专家被激活参与计算,不是所有专家都参与。这可以显著减少计算量和显存占用,提高模型的训练和推理效率,是MoE模型高效运行的关键技术之一。
-
分布式训练:分布式训练是将模型训练任务分布在多个计算节点或GPU上进行的技术。XTuner V1 通过优化通信和显存管理,支持在多个设备上高效训练超大规模模型,显著提升了训练速度和效率。
-
PyTorch FSDP(Fully Sharded Data Parallel):FSDP是PyTorch的一种分布式训练技术,通过将模型参数均匀切分到每个设备上,减少了显存占用。XTuner V1 基于FSDP开发,支持大规模分布式训练,提高了训练的可扩展性。
-
显存优化技术:XTuner V1 采用了如自动Chunk Loss机制和Async Checkpointing Swap等技术,有效降低了显存峰值。这些技术通过优化显存使用,支持更大规模的模型训练,减少了对硬件资源的需求。
-
通信掩盖技术:通信掩盖技术通过优化计算和通信的重叠,掩盖通信耗时。XTuner V1 利用这种技术减少了通信开销对训练效率的影响,提高了整体训练性能。
相关文章
暂无评论...