
AI Engineering Hub 是广受欢迎的开源项目,专注于大型语言模型(LLM)、检索增强生成(RAG)及 AI 智能体应用的系统教程与实战案例。项目能提供深入的理论解析,附有丰富的可执行代码示例,帮助学习者快速掌握核心技能。在 GitHub 上,项目已收获多度认可,核心内容被整理成一部 500 多页的 PDF 手册,极大地方便学习与传播。AI Engineering Hub 面向从入门者到开发者、研究人员在内的广泛群体,积极鼓励社区参与,共同促进 AI 技术的进步与创新。
AI Engineering Hub 课程概览
AI Engineering Hub 提供一套全面且实用的数据科学与机器学习学习资源,内容覆盖从基础到高阶的关键主题。课程主要分为两大板块:
- 深度学习:包括迁移学习、联邦学习、多任务学习等前沿学习范式,且涵盖混合精度训练、梯度检查点等优化技巧,深入讲解大语言模型的微调与部署策略。
- 经典机器学习:系统梳理特征工程、回归分析、决策树、聚类等传统方法,结合统计原理与实际案例(如应对数据漂移与缺失值),同时揭示常见误区(如随机分割数据的陷阱)。
资料中提供丰富的数据分析工具使用指南(如 Pandas、SQL)、可视化技巧(如桑基图、QQ图)及 Python 面向对象编程的高级用法。全文通过代码示例、可视化图表与实验对比,兼顾理论与实操,适合不同阶段的学习者。附带的评估工具有助于读者快速定位最需要学习的内容,实现高效提升。
课程核心内容
深度学习
学习范式
- 迁移学习:利用在相关任务上预训练好的基础模型,通过冻结大部分层并替换最后几层,适应小规模数据集的新任务。
- 微调:在预训练模型的基础上,对新数据进一步调整部分或全部模型权重,更好地适应目标任务。
- 多任务学习:设计共享层处理多个相关任务,每个任务拥有独立的输出分支,提升模型泛化能力,节约计算资源。
- 联邦学习:模型在分散的各用户设备上进行本地训练,将参数更新上传至中心服务器进行聚合,有效保护数据隐私。
- 主动学习:从少量已标注数据开始训练,模型自动筛选出不确定性高的样本进行人工标注,通过迭代方式优化模型,特别适用标注成本高昂的场景。
运行时与内存优化
- 动量:通过计算梯度的移动平均值来减少优化过程中的震荡,加速模型收敛。
- 混合精度训练:在前向传播和梯度计算时使用 float16 以提升速度,在权重更新时使用 float32 保证数值精度,通常需要配合损失缩放技术。
- 梯度检查点:通过只存储部分层的激活值,在反向传播时重新计算中间结果,牺牲一定计算时间换取显著的内存节省。
- 梯度累积:在小批量训练中,连续累积多个小批次的梯度后再执行一次权重更新,模拟大批量训练的效果。
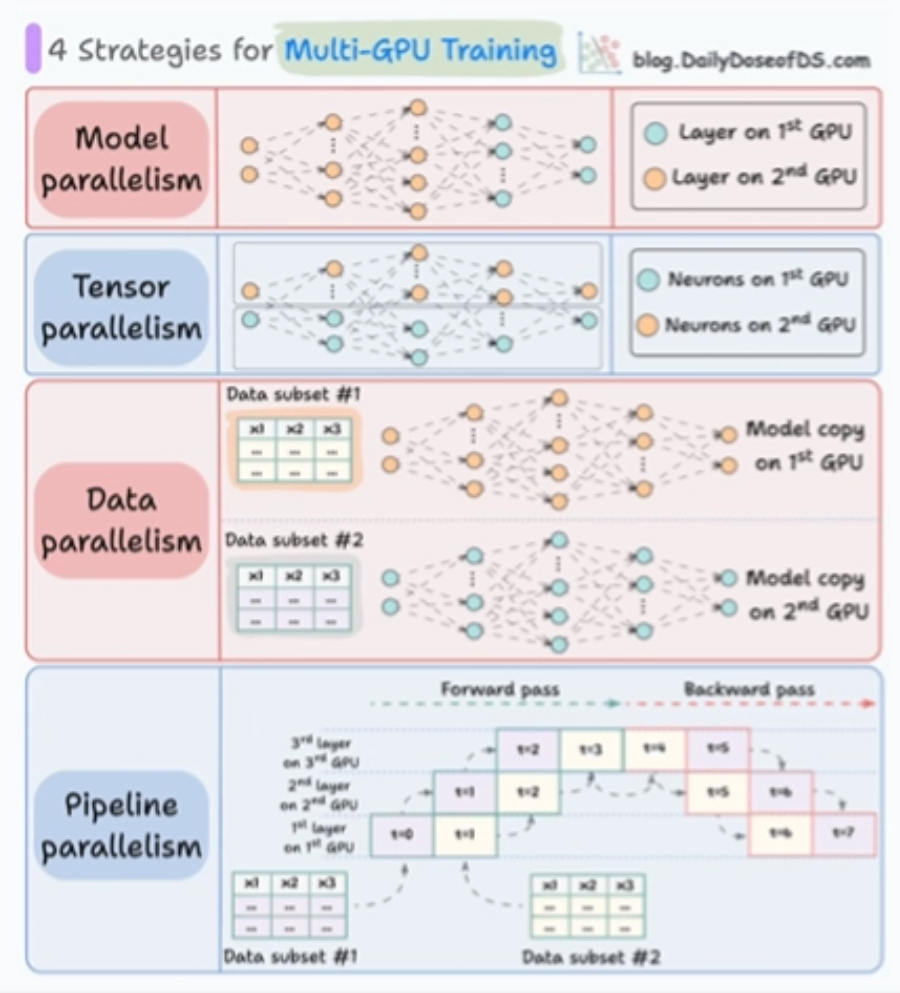
多 GPU 训练策略
- 模型并行:将模型的不同层分布到多个 GPU 上。
- 张量并行:将单个张量的运算(如大矩阵乘法)拆分到多个 GPU 上并行计算。
- 数据并行:将同一模型复制到多个 GPU,每个 GPU 处理不同的数据分片,训练完成后同步梯度。
- 流水线并行:将模型按层分段,采用微批次流水线处理,提高 GPU 的利用率。
其他重要主题
- 标签平滑:通过调整真实标签的分布,防止模型对预测结果过度自信,提升模型的泛化能力。
- 焦点损失:通过引入可调节的因子,降低易分类样本在总损失中的权重,缓解类别不平衡问题。
- Dropout 工作原理:在训练阶段随机“关闭”一部分神经元,对保留的神经元进行缩放,减少过拟合。
- CNN 中的 Dropout 应用注意:由于可能破坏卷积层的空间相关性,通常建议在全连接层使用 Dropout。
- 隐藏层与激活函数的作用:解释了深度网络中隐藏层如何逐层提取特征,及激活函数如何引入非线性。
- 训练前数据打乱:确保每个训练批次中的数据顺序是随机的,避免模型学习到无关的顺序模式。
模型压缩
- 知识蒸馏:用一个大型的“教师”模型指导一个小型“学生”模型的训练,实现模型压缩。
- 激活剪枝:识别、移除网络中重要性较低的神经元或连接,减少计算量。
部署相关
- 从 Jupyter Notebook 到生产部署:简化模型从开发环境迁移到生产环境的流程。
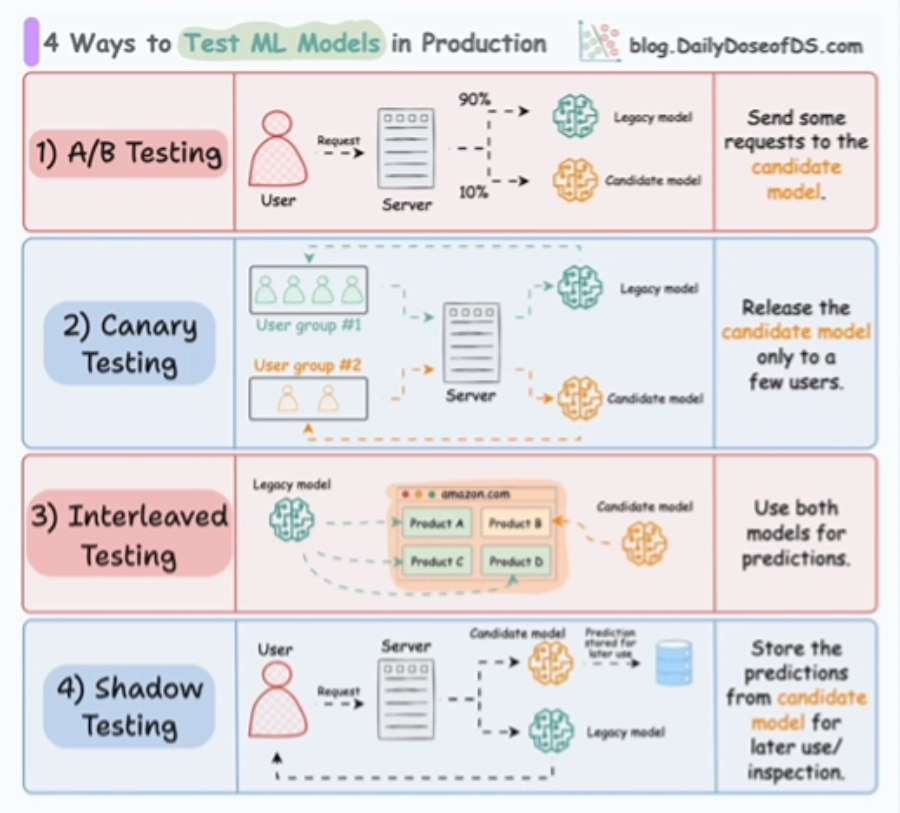
- 生产环境模型测试方法:包括 A/B 测试、影子部署等验证策略。
- 版本控制与模型注册:系统化管理模型的不同迭代版本,控制生产环境的发布流程。
大语言模型专题
- GPU 内存管理:分析训练大型语言模型时的显存占用瓶颈及优化方法。
- 全模型微调、LoRA 与 RAG 对比:全参数微调资源消耗大;LoRA 通过低秩适配实现高效微调;RAG 通过外部检索动态扩展模型知识。
- LLM 微调技术概览:详细介绍适配器微调、前缀微调等多种轻量化微调方法。
经典机器学习
机器学习基础
- 算法时间复杂度:对比分析 SVM、随机森林等 10 种常用算法的训练与预测时间复杂度。
- 核心数学概念:梳理 25 个在概率论、线性代数等领域的关键定义。
- 改进多分类概率模型:介绍 Platt Scaling 等概率校准方法。
- 模型改进无效的原因:分析数据质量、评估指标选择不当等潜在陷阱。
- 损失函数汇总:列出逻辑回归、SVM 等 16 种算法的损失函数,及交叉熵、Huber 损失等 10 种常见损失函数的适用场景。
- 数据集划分:阐述训练集、验证集和测试集的正确使用方式,避免信息泄露。
- 交叉验证技术:介绍 k 折交叉验证、留一法等五种方法及其应用步骤。
- 偏差-方差权衡与双下降现象:探讨模型复杂度与泛化误差之间的复杂关系。
统计基础
- MLE 与 EM 算法区别:最大似然估计适用于完整数据,EM 算法用在处理存在隐变量的情况。
- 置信区间与预测区间:解释两者在概念和计算上的差异。
- OLS 的无偏性:从数学角度推导普通最小二乘法为何是无偏估计。
- 分布相似性度量:介绍巴氏距离与马氏距离(后者考虑了数据的协方差结构)。
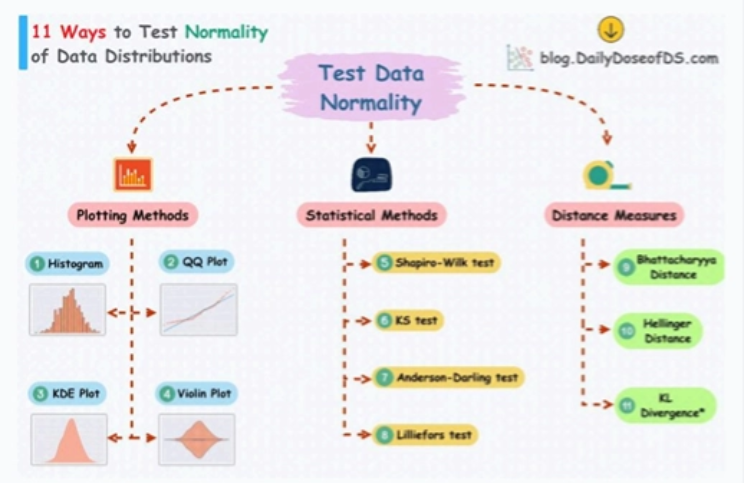
- 正态性检验:列举包括 Shapiro-Wilk 检验和 QQ 图在内的 11 种检验数据正态性的方法。
- 概率与似然:辨析这两个核心概念及其与最大似然估计的联系。
- 关键概率分布:概述泊松分布、指数分布等 11 种分布在机器学习中的应用。
- 连续概率分布的常见误解:澄清概率密度函数的真实含义。
特征工程与选择
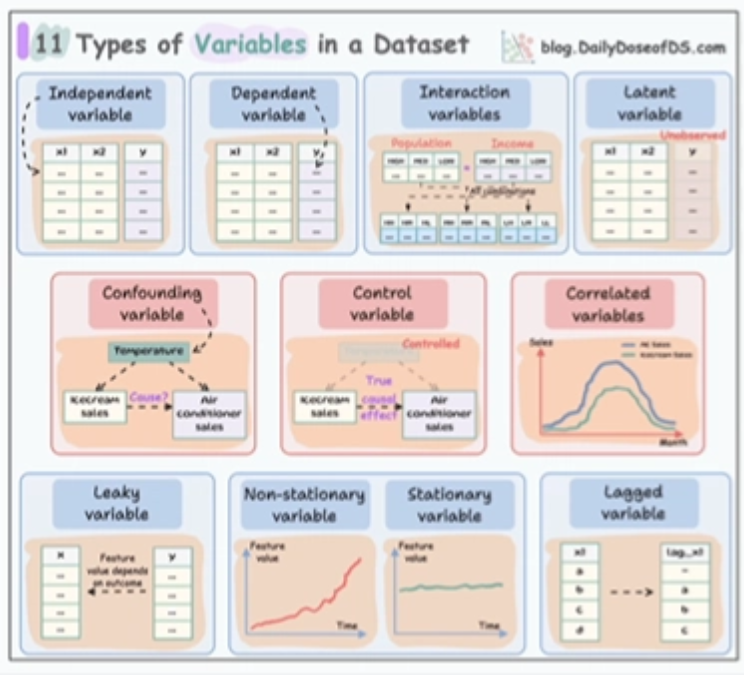
- 变量类型:区分名义变量、序数变量、连续变量等 11 种数据类型,指导预处理策略。
- 周期性特征编码:对小时、星期等特征使用正弦余弦编码,保持其周期性。
- 特征离散化:将连续特征划分为多个区间,在线性模型中增强鲁棒性。
- 分类数据编码:比较独热编码、目标编码、哈希编码等 7 种方法的优缺点。
- 特征重要性评估:通过随机打乱特征值,观察模型性能变化来量化重要性。
- 探针特征选择:引入随机噪声特征,剔除重要性低于噪声的特征,提升模型泛化性。
回归分析
- MSE 的数学特性:均方误差的凸性保证收敛,对异常值敏感。
- Sklearn 线性回归无超参数原因:因采用解析解直接求解,无需迭代优化。
- 泊松回归 vs. 线性回归:泊松回归适用于计数数据,使用对数连接函数。
- 虚拟变量陷阱:在编码类别变量时,需避免完全多重共线性。
- 广义线性模型:统一框架,通过连接函数扩展线性回归至多种数据分布。
- 零膨胀回归:针对包含大量零值的计数数据,结合逻辑回归和泊松回归进行建模。
决策树与集成方法
- 随机森林压缩:尝试将随机森林的规则提炼为一棵简化的决策树,提升可解释性。
- 决策树的过拟合倾向:因天生低偏差,需通过剪枝或集成来控制方差。
- AdaBoost 原理:迭代调整样本权重,聚焦难样本,组合多个弱分类器。
- 袋外验证:用随机森林构建时未采样的样本进行验证,无需单独划分验证集。

降维技术
- PCA 方差解释:通过选择主成分保留大部分方差,实现降维。
- t-SNE 与 PCA 对比:t-SNE 擅长可视化局部结构,PCA 保留全局方差。
- 核 PCA:通过核函数处理非线性可分数据。
聚类分析
- KMeans vs. 高斯混合模型:KMeans 为硬聚类,GMM 为软聚类(概率归属)。
- DBSCAN++:优化传统 DBSCAN,减少邻域查询次数,加速计算。
- HDBSCAN:层次化 DBSCAN,能自动确定簇数量并识别不同密度的簇。
相关性分析
- 皮尔逊相关性的局限性:只能度量线性关系,Spearman 相关可捕捉单调关系。
- Anscombe 四重奏的启示:强调可视化的重要性,相同的统计量可能对应截然不同的数据分布。
缺失数据处理
- 缺失机制:区分完全随机缺失、随机缺失和非随机缺失,采取相应处理策略。
- MissForest 插补:使用随机森林模型迭代预测缺失值,适用混合类型数据。
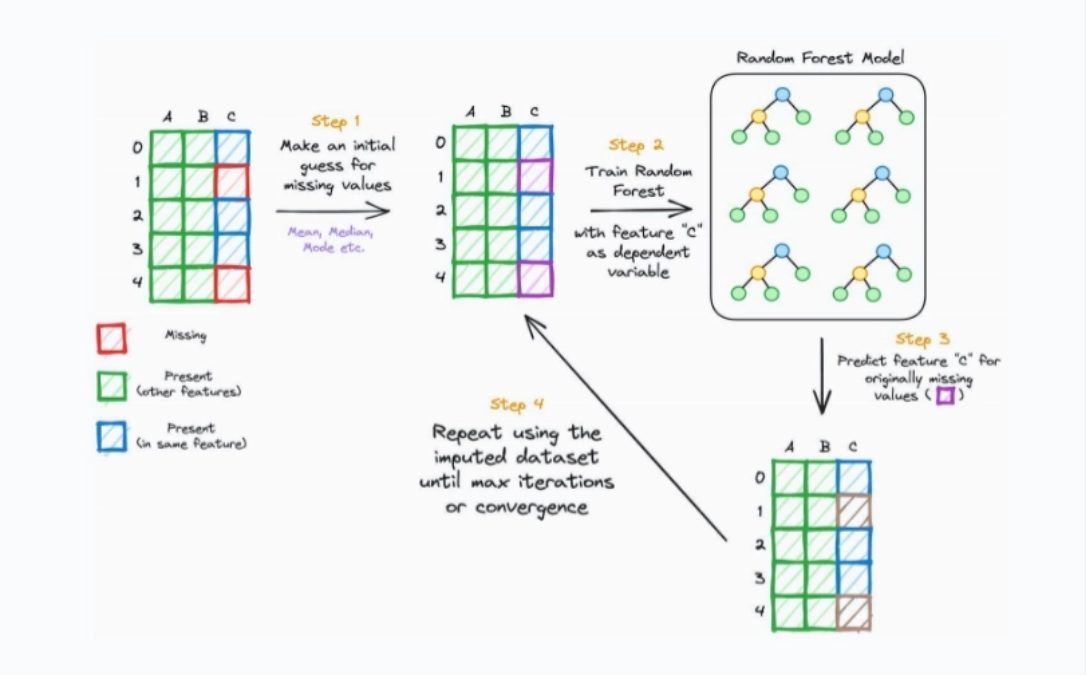
数据分析工具
- 多工具语法对照:对比 Pandas, Polars, SQL, PySpark 在常见操作(如分组聚合)上的语法差异。
- GPU 加速 Pandas:介绍 RAPIDS cuDF 库,用 GPU 并行计算加速数据处理。
SQL 高级操作
- 半连接:使用
WHERE EXISTS子句高效筛选存在于另一表中的记录。 - 慎用 NOT IN:当子查询结果包含 NULL 时可能导致意外结果,推荐使用
NOT EXISTS或LEFT JOIN ... IS NULL替代。
Python 面向对象编程
- 描述符:通过实现
__get__和__set__方法精确控制属性访问,是@property等装饰器的底层机制。 - PyTorch 中的 forward 调用:解释为何不直接调用
forward()方法,通过调用模型实例来触发前向传播,保持计算图和钩子机制的完整性。
AI Engineering Hub的项目地址
- GitHub仓库:https://github.com/patchy631/ai-engineering-hub
AI Engineering Hub的适用人群
- 初学者:提供清晰的基础概念与实操指南,帮助零基础学习者轻松入门 AI 领域。
- 开发者和实践者:提供可直接运行的代码示例与项目案例,助力在实际工作中应用 AI 技术。
- 研究人员:汇集前沿技术动态与研究案例,方便学术交流与进一步探索。
- 数据科学家:提供结合 AI 技术的数据处理与模型优化方法,提升数据分析与建模效率。
- 技术爱好者:分享最新工具、框架与实战经验,满足对 AI 新技术的好奇心与学习需求。
AI Engineering Hub的资料下载地址
AI Engineering Hub下载地址:https://url23.ctfile.com/f/65258023-1546369369-231d59?p=8894 (访问密码: 8894)
相关文章
暂无评论...