
FireRedASR是什么
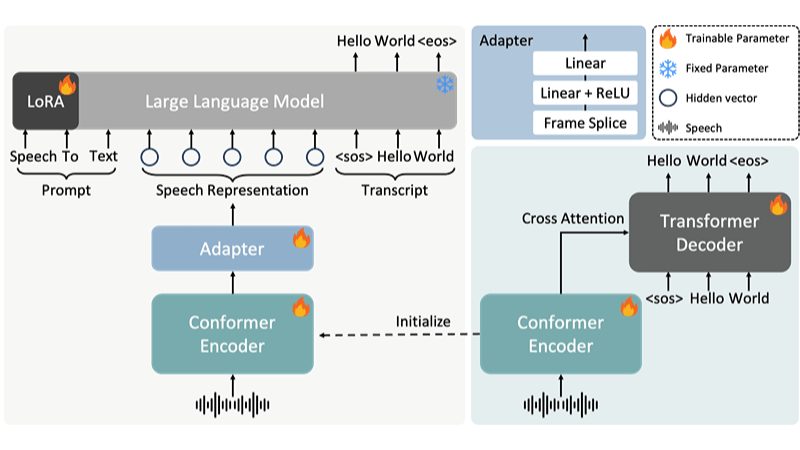
FireRedASR 是小红书 FireRed 团队开源的工业级自动语音识别(ASR)模型家族。包含两种核心结构:FireRedASR-LLM 和 FireRedASR-AED。前者采用 Encoder-Adapter-LLM 框架,结合文本预训练 LLM,专为极致准确率设计,在普通话基准测试中达到 3.05% 的平均字符错误率(CER),超越了 3.33% 的最新 SOTA。后者基于经典的 Attention-based Encoder-Decoder 架构,通过扩展参数至 1.1B,平衡了高准确率与推理效率,平均 CER 为 3.18%,优于 12B 参数的 Seed-ASR。FireRedASR 支持普通话、中文方言和英语,尤其在歌词识别方面表现出色。为需要高准确率和多语言支持的 ASR 应用提供了强大的解决方案。
FireRedASR的主要功能
-
高准确率的普通话识别:FireRedASR-LLM 在普通话基准测试中达到 3.05% 的平均字符错误率(CER),超越了 3.33% 的最新 SOTA,为极致的 ASR 准确率而生。
-
平衡准确率与效率的识别:FireRedASR-AED 在保持高准确率的同时,通过扩展参数至 1.1B,成功平衡了 ASR 语音识别的准确率与推理效率,平均 CER 为 3.18%,优于 12B 参数的 Seed-ASR。
-
多语言支持:支持普通话、中文方言和英语,满足不同语言环境下的语音识别需求。
-
歌词识别能力出色:在歌词识别方面表现出色,能够准确识别歌曲中的歌词内容。
FireRedASR的官网地址
- Github仓库:https://github.com/FireRedTeam/FireRedASR
- HuggingFace模型库:https://huggingface.co/FireRedTeam/FireRedASR-AED-L
- arXiv技术论文:https://arxiv.org/pdf/2501.14350
FireRedASR相关的人工智能知识
-
自动语音识别(ASR):ASR 是人工智能中将语音信号转换为文本的技术,通过复杂的算法和模型理解语音内容。FireRedASR 作为 ASR 模型,利用深度学习技术实现高准确率的语音转文本,广泛应用于语音助手、视频字幕生成等领域。
-
深度学习:深度学习是基于人工神经网络的机器学习技术,通过多层神经网络学习数据的复杂模式。FireRedASR 利用深度学习从大量语音数据中提取特征,训练出高性能的语音识别模型,是实现高准确率的关键技术。
-
编码器-解码器架构:这是一种常用于序列到序列任务的架构,编码器将输入序列(如语音信号)编码为中间表示,解码器再将其解码为目标序列(如文本)。FireRedASR-AED 采用此架构,有效处理语音到文本的转换任务。
-
注意力机制:注意力机制使模型在处理数据时能聚焦于重要部分,提高处理效率和准确性。在 FireRedASR 中,注意力机制帮助模型更好地捕捉语音中的关键信息,提升语音识别的性能。
-
预训练模型与微调:预训练模型是在大规模数据上预先训练好的模型,微调是将其适应特定任务的过程。FireRedASR-LLM 结合预训练的 LLM,通过微调使其在语音识别任务中表现出色,提升了模型的泛化能力。
-
数据增强:数据增强通过对数据进行变换增加数据多样性,提高模型的泛化能力。在 FireRedASR 训练中,数据增强使模型能更好地处理不同条件下的语音信号,提升性能。
相关文章
暂无评论...